[Oli Wright] is back again with another installation of CRT shenanigans. This time, the target is the humble analog oscilloscope, specifically a Farnell DTV12-14 12 MHz dual-channel unit, which features a handy X-Y mode. The result is the Velociraster, a simple (in hardware terms) Raspberry Pi Pico based display driver.
Using a Pico to drive a pair of AD767 12-bit DACs, the outputs of which drive the two ‘scope input channels directly, this breadboard and pile-of-wires hack can produce some seriously impressive results. On the software side of things, the design is a now a familiar show, with core0 running the application’s high-level processing, and core1 acting in parallel as the rendering engine, determining static DAC codes to be pushed out to the DACs using the DMA and the PIO.
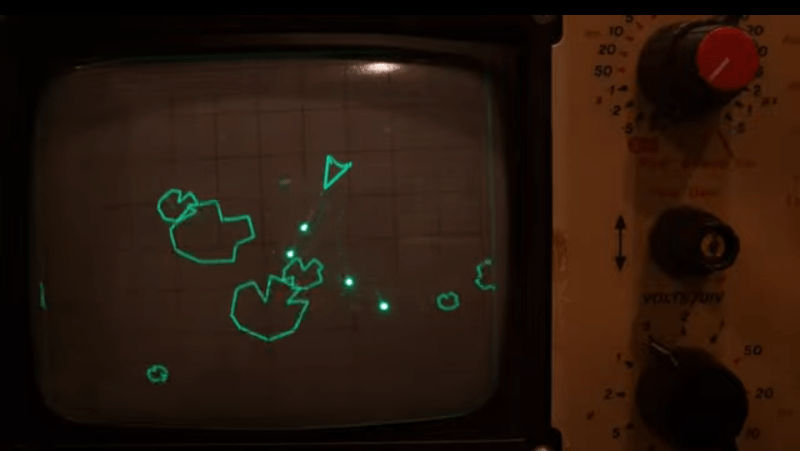
The first demo is in vector mode, simply showing some simple shapes, to get an idea of the accuracy and linearity of the system. Next [Oli] shows a slick demo of a ‘starfield’ type effect, which renders different point brightnesses by accurately controlling the beam hold time. Next up is an Asteroids-like game —which should be familiar to many — that shows off vector rendering with some nice particle effects visible due to the CRTs wide dynamic range.
of the system. Next [Oli] shows a slick demo of a ‘starfield’ type effect, which renders different point brightnesses by accurately controlling the beam hold time. Next up is an Asteroids-like game —which should be familiar to many — that shows off vector rendering with some nice particle effects visible due to the CRTs wide dynamic range.
[Oli] then goes on to show off raster mode, with an accurate-looking space invaders clone, followed by a static image showing some rudimentary grey-scale control mixed in with vector-mode graphics! There is an extra-special treat at the end of the video, which you’re not going to want to miss. No spoilers!
Some example code can be found in the examples repo, with the rendering library available here, for those who wish to play along at home.
Obviously driving a scope in XY mode with a computer is not a new trick, we’ve seen someone drive a (digital) Rigol to that effect, but CRTs just look, you know, cooler.